Label360: An Implementation of a 360 Segmentation Labelling Tool

The image above shows an example of the segmentation mask overlaying on top of the 360 image we got from our drone. This image is labeled by one of our in-house labelers.
Semantic segmentation is one of the key problems in computer vision. It is important for image analysis tasks, and it paves the way towards scene understanding. Semantic segmentation refers to the process of assigning each pixel of the image with a class label, such as sky, road, or person. There are numerous applications that nourish from inferring knowledge from imagery. Some applications include self-driving vehicles, human-computer interaction, and virtual reality.
360 images and videos are popular nowadays for applications like game design, surveillance systems, and virtual tourism. Researchers use 360 images as input for object detection and semantic segmentation models. However, researchers usually convert 360 images to normal field-of-view first before labelling them. For example, Stanford 2D-3D-Semantics Dataset has 360 images, but the segmentation datasets are sampled images from equirectangular projection with different field-of-views [1]. Other 360 datasets only have labeled saliency but not segmentation, such as Salient360 and video saliency dataset [2][3]. Lastly, there are 360 datasets with many equirectangular images, but they are not yet labeled, such as Pano2Vid and Sports360 [4][5].
To our knowledge, there are no public annotation tools that are suitable for 360 images, and so we decided to build a semantic segmentation annotator from the ground up that is specifically for 360 images, hoping to increase the amount of research relating to semantic segmentation on equirectangular images.
The first problem with labelling 360 images is that it is difficult to label and recognize objects at the top and bottom of the equirectangular images. This is because when spherical surface projects to a plane, the top and bottom of the sphere gets stretched to the width of the image.
Converting to cubemap solves that problem but raises another: Objects that span across two faces of the cube are harder to label. To deal with the two problems above, we use cubemap and provide drawing canvas with expanded field-of-view. We will describe these methods in detail later on.
Our 360 segmentation tool
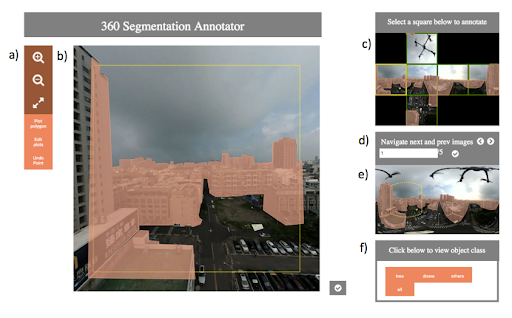
UI Components:
- Toolbar: It has plotting, editing, zooming, and undoing functions.
- Drawing canvas: The user can annotate on the drawing canvas. The canvas displays a face of the cubemap with an expanded field-of-view.
- Cubemap viewer: The user can select a face in the cubemap to annotate and view annotations in cubemap.
- Image navigator: The user can navigate to different images.
- Equirectangular viewer: The user can see mapped annotations in equirectangular view in real-time.
- Class selector: The user can view annotations of different classes.
In the cubemap viewer, the border color of the faces in the cubemap canvas indicates the status of the annotations: Faces with existing annotations are indicated using a green border, and those without using a red border. The current face shown in draw canvas is indicated in yellow. We will describe drawing canvas in detail later on.
User journey:
Annotation Process:
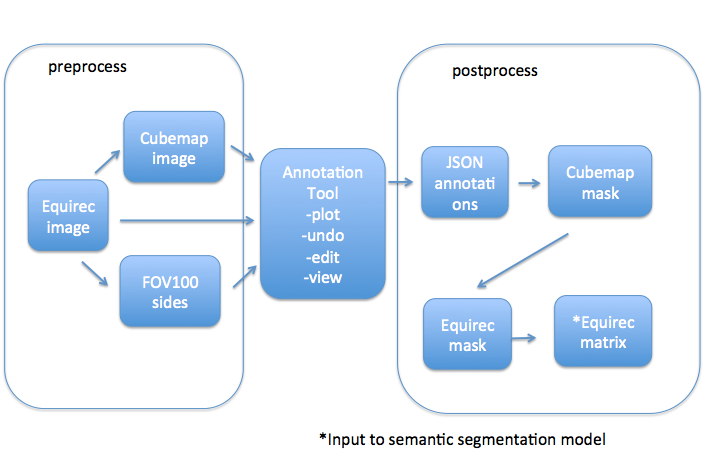
The flow chart below shows the annotation process from equirectangular image to the input to the semantic segmentation model.
Design:
- The use of cubemap solves the problem of distortion at the top and bottom of 360 images
The main difference between 360 images and normal field-of-view images is that the top and bottom of 360 images are distorted. This distortion results from points near the top and bottom of the images being stretched to fit the full width of the image. If we directly place the equirectangular image into a widely used annotation tool, it is difficult to label the top and bottom of the image. Moreover, it is harder and more time consuming to label the curves at those areas using polygons.
To make it easier to recognize and label equirectangular images, we designed our annotator to display cubemaps instead. The image below shows the conversion between a cubemap (left) and an equirectangular image (right).
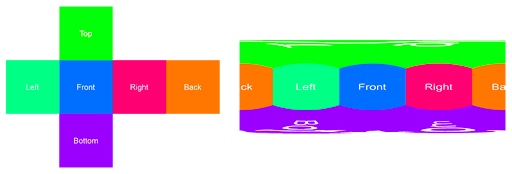
By converting the equirectangular image to a cubemap, we allow annotators to see objects in a normal field-of-view. In addition, we allow users to annotate each side of the cubemap separately. Below shows our original image (right) and the cubemap we convert to (left).


- Annotation on an expanded field-of-view and real-time display of equirectangular annotations solve the border problem
As we developed the segmentation annotator, we found out that the borders between faces of the cube have gaps or do not appear connected. This may cause a problem because a road that crosses several sides of the cube may be discontinuous. Moreover, it is difficult to draw near the borders. The annotator has to spend a lot of time adjusting the points to the borders.


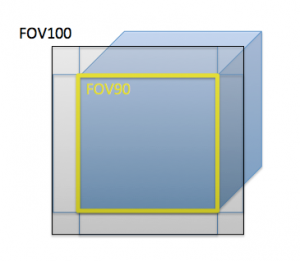
Images above show our method of dealing with the border problem. The drawing canvas has a 100 degree field-of-view on one face of the cube. The yellow square inside the drawing canvas has a 90 degree field-of-view. Annotators can label objects in the expanded field-of-view, but only the annotations inside the normal field-of-view will be saved.
We are also able to use the cubemap viewer and the equirectangular viewer to see how the annotations turn out and whether annotations that cross different sides are connected properly.


The mask on the left (above) is an example of discontinuous objects across different faces of the cubemap. There are white borders around each face. Objects don’t connect well, and they are likely to be labeled with different classes. The mask on the right is an example of having continuous objects across different faces of the cubemap.
Summary:
Our 360 annotation platform separates us from other annotation tools with our features specifically designed for 360 images, such as being able to annotate a specific side of the cubemap, our distinct drawing canvas with an expanded field-of-view, and the real-time display of annotations in equirectangular viewer. These features solve the problems of using off-the-shelf annotation platforms to annotate 360 images, such as the distortion problem and the border problem mentioned earlier in the article. We hope that the implementation of our 360 segmentation labelling platform can produce more semantic segmentation datasets for 360 images, and thus nourish the growth of research relating to computer vision task of semantic segmentation on 360 images.
Reference:
- Armeni, Iro, et al. “Joint 2d-3d-semantic data for indoor scene understanding.” arXiv preprint arXiv:1702.01105 (2017).
- Gutiérrez, Jesús, et al. “Introducing UN Salient360! Benchmark: A platform for evaluating visual attention models for 360° contents.” 2018 Tenth International Conference on Quality of Multimedia Experience (QoMEX). IEEE, 2018.
- Zhang, Ziheng, et al. “Saliency detection in 360 videos.” Proceedings of the European Conference on Computer Vision (ECCV). 2018.
- Bares, W., et al. “Pano2Vid: Automatic Cinematography for Watching 360◦ Videos.”
- Hu, Hou-Ning, et al. “Deep 360 pilot: Learning a deep agent for piloting through 360 sports videos.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017.

