Expanding Computer Vision Multi-View Stereo Capabilities: Automatic Generation of 3-dimensional Models via 360 Camera Footage

As the world we live in is three-dimension, 3D model is the most iconic representation of our world. 3D modeling allows people to see what they would not see when viewing in 2D. It gives people the ability to physically see how much real estate an object takes from all perspectives. But compared to generated from scratch, we are also able to build 3D models from video automatically.
Taiwan AI Labs has built a virtual aerial website: droneye.tw. This website has great 360 video resources. It triggers an idea. Can we use 360 videos to generate high-quality 3D model within only few flights in order to minimize the cost to obtain the 3D model? Indeed, it is feasible no matter using stereo-views computer vision algorithm or deep learning approach. The concept of 3d model reconstruction can be illustrated as figure 1 that we are able to solve 3D object coordinate from the same point on the at least 2 images.
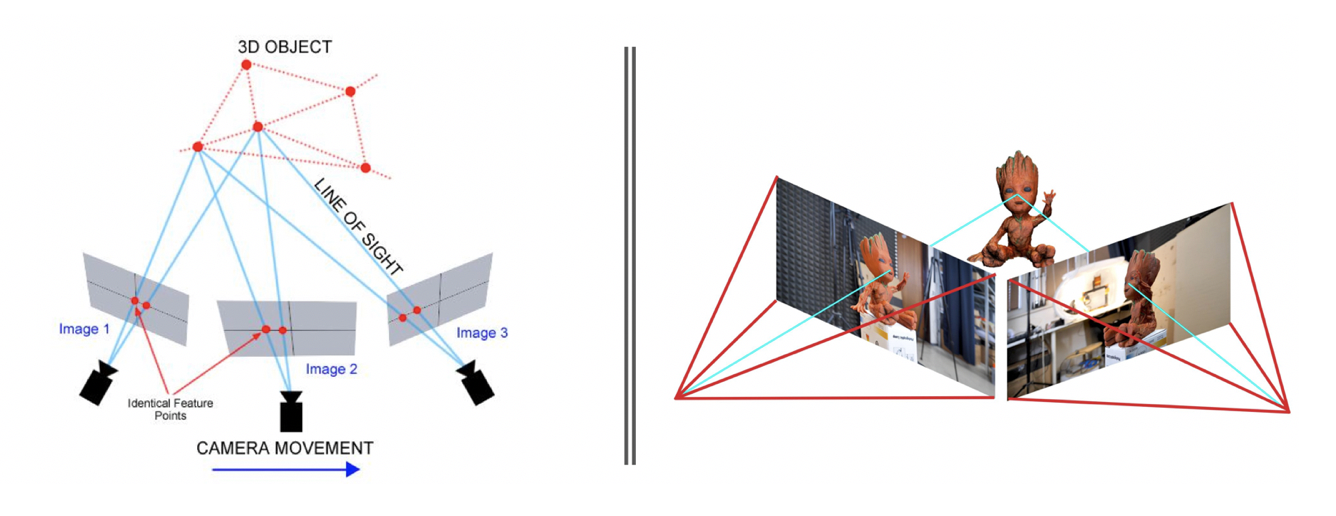
Fig 1. Concept of 3D Reconstruction (Modified from Tokkari etc., 2017)
360-degree cameras capture the whole scene around a photographer in a single shot. 360 cameras are becoming a new paradigm for photogrammetry. In fact, the camera can be pointed to any direction, and the large field of view reduces the number of photographs.[1] The camera we used at the former flight is Virb 360, which record the video in panoramic ways. As a result, it cannot be used to reconstruct the 3D model directly. We have to project its equirectangular images to any FOV perspective images (Fig 2.) or cubemap so we are able to take advantage of these images to build our 3D models. It can also support reconstructing the 3D model inside the building, we can choose the image angle we want or just choose cubemap format, it will automatically use the reprojection images to generate 3D model.
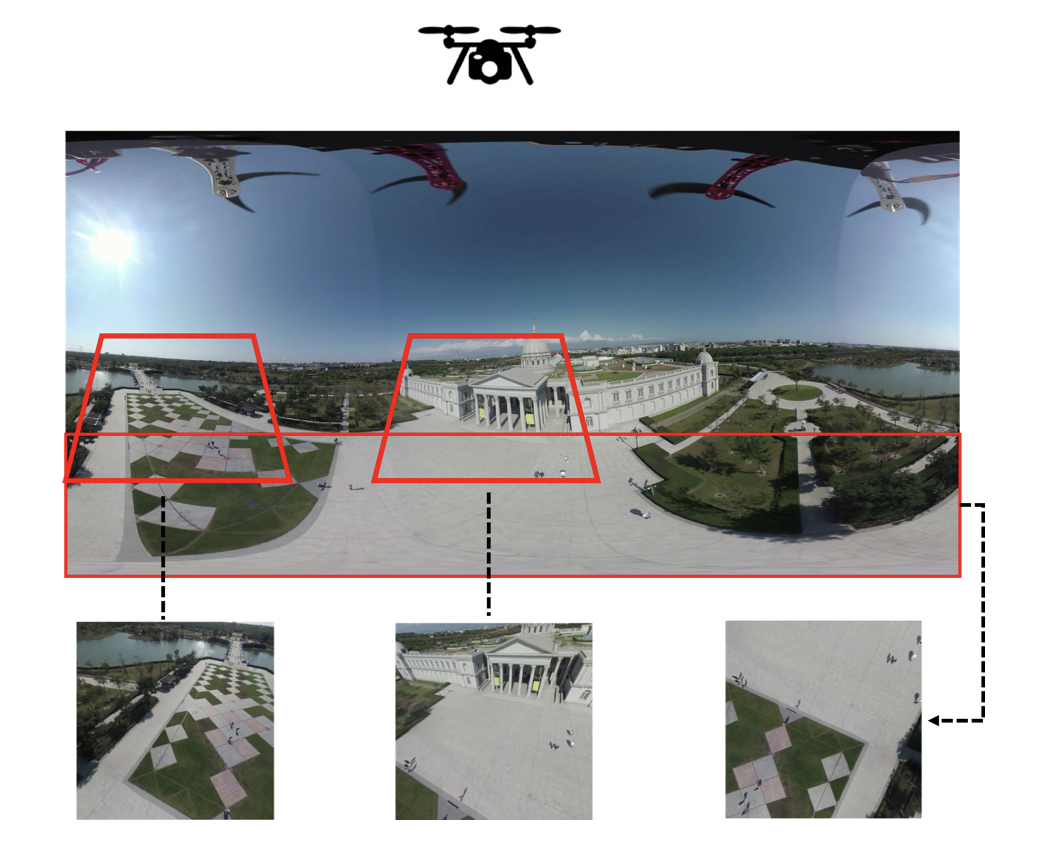
Fig 2. Different angle of views from drone
First of all, tanksandtemples website which present a benchmark for image-based 3D reconstruction have indicated results of 3D model generated by deep learning still do not surpass the stereo-views computer vision algorithm. We have implemented both algorithms and compare the results. The test input is 16 high resolution NTU campus photos from drone. The deep learning algorithm we use is R-MVSNet, it’s an end-to-end deep learning architecture for depth map inference from multi-view images.[8] The computer vision algorithm is Structure from Motion and semi-global matching. We can tell from the result that state-of-the-art deep learning algorithm of 3D model still has a way to go. Nonetheless, deep learning algorithm for 3D reconstruction undoubtedly has a great prospect in the future.
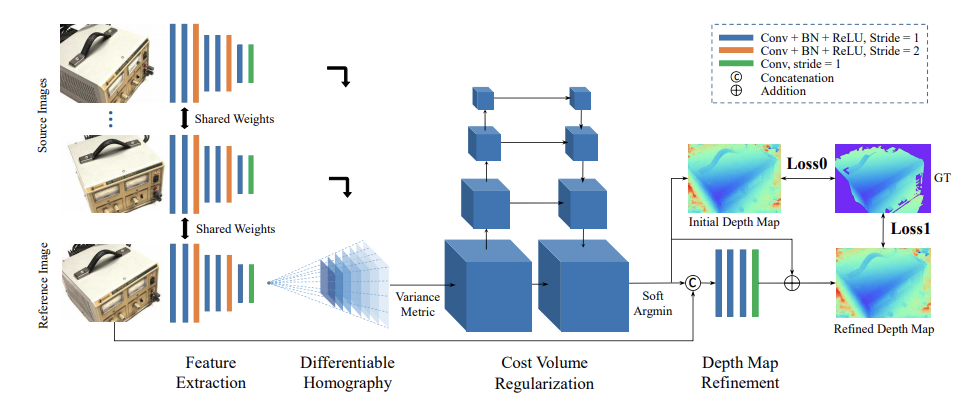
Fig. The Architecture of R-MVSNet (Yao etc, 2019)
Table. Point Cloud results of deep learning and conventional computer vision
|
Semi-Global Matching |
R-MVSNet |
 |
 |
Base on the above statement, we decide to apply Structure from Motion & patch matching algorithm to reconstruct our 3d model. The main steps include sparse reconstruction and dense reconstruction. In the sparse reconstruction, we use SIFT to match features. Now we have the corresponding points on each image. Then we use bundle adjustment to adjust the camera extrinsic and intrinsic by least square method.[4] After these sub-steps we obtain the more accurate camera extrinsic and intrinsic for the dense reconstruction. In the dense reconstruction, first we take advantage of camera position to calculate the depth map of each image by semi-global matching.[2] Then we fuse the neighbor depth maps to generate 3d point cloud. However, data volume of point cloud is relatively huge, we simplify the point to Delaunay triangulations or so-called mesh, which turn the points into planes.[5] Final, we texture the mesh with the corresponding images.[7]
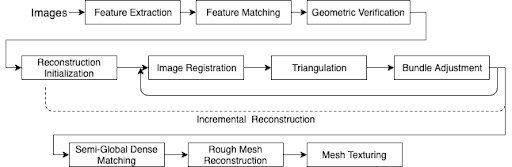
Fig. 3D reconstruction pipeline (Bianco etc, 2018)
Table. Result of NTU Green House
| Real Picture | 3D Model |
 |
|
Table. Result of Tainan Qingping Park
| Real 360 Picture |
3D Model |
 |
 |
Although 360 video has the advantage of multi-views in single frame, it has significant drawbacks such as unstable camera intrinsic and when projecting to the perspective images, the resolution will decrease drastically. Thus, we adopt super resolution algorithm – ESRGAN in order to overcome low-quality of images. Indeed, this strategy not only increases the details of the 3d models especially when texturing the mesh but also densify the point cloud. In order to obtain better results, we can train our own model on the “Taiwan landscape” the prevent bias of the unsuitable pre-trained model and to meet the special needs of drone data in Taiwan.
| Bilinear x4 | SR x4 | |
 |
 |
 |
Nonetheless, ESRGAN doesn’t restore the original information, it learns high frequency information in the images by inference.[9] Due to the fact, it would hurt the quality of structure from motion. If we would like to take advantage of the better results of super-resolution and also maintain the quality of Structure from Motion, we could use the SR images as input at the step of dense matching. To sum up, by using state-of-the-art deep learning algorithm such as super-resolution (ESRGAN), we may be able to reduce some drawbacks of 360 video and generate the desired 3D models.

Fig. Chimei Museum

Fig. Lin Mo-Niang Park

Fig. Tzu Chi Senior High School
Reference
- Barazzetti, L., Previtali, M., & Roncoroni, F. (2018). Can we use low-cost 360 degree cameras to create accurate 3D models?. International Archives of the Photogrammetry, Remote Sensing & Spatial Information Sciences, 42(2).
- Barnes, C., Shechtman, E., Finkelstein, A., & Goldman, D. B. (2009). PatchMatch: A randomized correspondence algorithm for structural image editing. In ACM Transactions on Graphics (ToG) (Vol. 28, No. 3, p. 24).
- Bianco, S., Ciocca, G., & Marelli, D. (2018). Evaluating the performance of structure from motion pipelines. Journal of Imaging, 4(8), 98.
- Fraundorfer, F., Scaramuzza, D., & Pollefeys, M. (2010). A constricted bundle adjustment parameterization for relative scale estimation in visual odometry. In 2010 IEEE International Conference on Robotics and Automation (pp. 1899-1904). IEEE.
- Jancosek, M., & Pajdla, T. (2014). Exploiting visibility information in surface reconstruction to preserve weakly supported surfaces. International scholarly research notices.
- Shen, S. (2013). Accurate multiple view 3d reconstruction using patch-based stereo for large-scale scenes. IEEE transactions on image processing, 22(5), 1901-1914.
- Waechter, M., Moehrle, N., & Goesele, M. (2014). Let there be color! Large-scale texturing of 3D reconstructions. In European Conference on Computer Vision (pp. 836-850).
- Wang, X., Yu, K., Wu, S., Gu, J., Liu, Y., Dong, C.,& Change Loy, C. (2018). Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 0-0).
- Yao, Y., Luo, Z., Li, S., Fang, T., & Quan, L. (2018). Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 767-783).