Ensure High Availability for Services: Endpoint Monitoring with AWS
HA and Monitoring
Availability is a quality attribute that, in general, refers to the degree to which a system is in an operable state. High availability then describes the set up of infrastructure that prevents a single point of failure and decreases service downtime. In Taiwan AILabs, the Engine team focuses on assuring not only developers but also end-users of a high level of service reliability and operational performance.
Monitoring is one of the characteristics that help us achieve high availability. We utilize production monitoring to learn how our services are performing in runtime and reduce the time to detect and mitigate failure, which refers to TTD and TTM.
AWS Route53 Health Check
To perform production monitoring and maintain high availability at the same time, we need to ensure there will not be a single point of failure for our monitoring service. That being said, if we run the monitoring service on a single instance and from a fixed location, the failure of the monitored endpoints will be masked if the instance is down. We will never know if the monitoring service and the endpoints are alive as we will not be receiving any alerts.
AWS Route 53 then becomes our go-to option for monitoring external endpoints. Route 53 has its health checkers located in multiple availability zones around the world. When we create a health check on route 53, health checkers across the world will start sending requests to the endpoint, determining if the endpoint is healthy and operational based on response time and number of responses within the failure threshold.
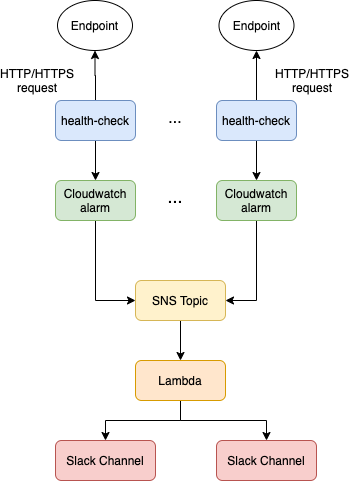
We utilized the “multiple availability zones” characteristic of Route 53 health check to maintain high availability for our monitoring service. Even if one of the health checks in one AZ breaks down, the health checkers from other AZs will still be sending HTTP requests to the endpoint we are monitoring, ensuring high availability for our services. The basic architecture of our monitoring service can be presented as the diagram below.

Figure 1. The architecture of the monitoring service
Route 53 health check will be sending HTTP/HTTPS requests to the endpoints that we would like to monitor (e.g., ailabs.tw). We will then connect our health checks to CloudWatch alarms respectively. Whenever Route53 health check switches the state of the endpoint (e.g., HEALTHY to ALARM, or ALARM to HEALTHY), the alarm on CloudWatch will be triggered. In order to receive notifications when the alarm is triggered, we will need to configure an SNS topic with the CloudWatch alarm and subscribe to a lambda function that would route the content of the alarm (in JSON format) to a slack channel.
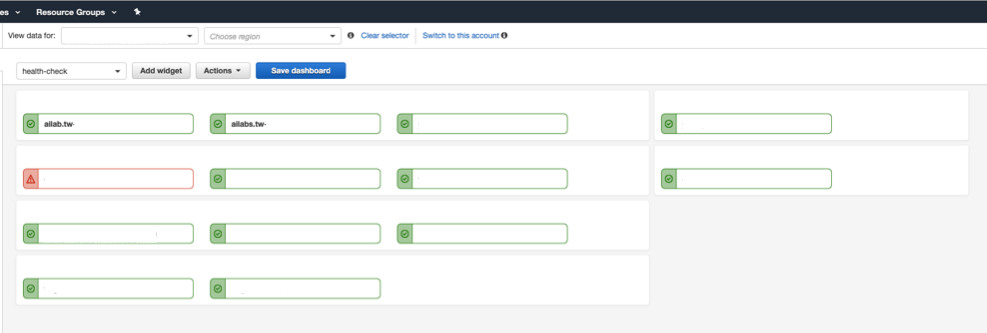
Figure 2. Health checks on CloudWatch Dashboard
IaC
To manage the infrastructure that we deploy on AWS more efficiently and automatically, we adopted the concept of Infrastructure as Code (IaC). Infrastructure as Code is the process of managing infrastructure in a file or files rather than manually configuring resources in a user interface[1]. It helped us to keep track of the resources that we’ve deployed so that we can control the budget and manage our resources more easily.
We developed a Terraform module that allows us to automatically provision 7 resources, including IAM role, health check, CloudWatch alarm, SNS topic, topic subscription, Lambda, and Lambda permission on to AWS in a single command: terraform apply. Developers who would like to monitor an external webpage would only need to specify the domain names, the port, the protocol(HTTP, HTTPS or TCP), the webhook, and the channel name of their slack channel in a configuration file (main.tf) and run `terraform apply`.

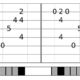
Figure 3. Example Usage of the module (written in HCL)
In addition to the Terraform module, the Engine team also developed a CI/CD pipeline for the repository that provides resources on AWS. Once the user pushes their configuration file (main.tf) to the repository in GitLab, the CI/CD pipeline will be triggered and start running automated scripts to build and test the configuration. After validating the configuration, users can deploy the resources on AWS without installing Terraform on their local machine since the deploying job will be done by the Docker executor on GitLab and we’ve already installed Terraform on the docker image. The CI/CD practice not only helps create an effortless deployment for engineers but ensures that all the infrastructure deployed to AWS complies with the standards of Terraform and Engine team standards.
Reference
[1] Infrastructure as Code with Terraform | Terraform – HashiCorp Learn. (2020). Retrieved 3 August 2020, from https://learn.hashicorp.com/terraform/getting-started/intro?_ga=2.74354834.1030159239.1596423434-594189736.1592893931