Speaker Verification and Speaker Retrieval
A. Introduction
Speaker verification is the task that given two segments of audio signal, we are supposed to verify whether both signals came from the same identity of the speaker or not. While inferencing, we first transform the audio signal into the corresponding speaker embedding, then calculate the similarity between two embeddings which is used to compare with the certain threshold later.
Speaker Retrieval is the task that given a paragraph of audio content, usually long, and a segment of audio represented one specific speaker identity as the input, we have to precisely point out the corresponding parts in the audio paragraph which owns the same identity as the input signal. In our experiment setting, we construct a pool set which includes a plenty of voice segments of several speakers, along with a target set which is composed of voice segments of speakers same as those in the pool set, each speaker has one corresponding segment within the target set.
In this article, we will first introduce the results of the speaker verification task and several skills to improve the performance, then show a new method that add a quantization part in the loss function, in order to fasten the process and reduce the memory usage in the speaker retrieval task.
B. Speaker Verification
First, we utilize four different speaker embedding models [1][2][3][4] on three datasets [5][6][7] and evaluate the performance of the results through two metrics. Also note that pyannote.audio (pyannote) and Efficient-TDNN (sugar) are both pretrained on the voxceleb dataset, while ECAPA-TDNN (spkrec) is pretrained on the cnceleb dataset.

In the result, we can quickly observe that the language information somehow makes an impact on the performance of the speaker verification task. To alleviate such influence, we implement several skills toward the speaker embeddings generated from the pre-trained models, including the concatenation and domain adaptation.
The table below shows the speaker verification results generating from the concatenated embeddings. The corresponding models are pretrained Efficient-TDNN (A), pretrained ECAPA-TDNN (B), Efficient-TDNN trained on cnceleb for 12 epochs (C), and Efficient-TDNN trained on cnceleb for 64 epochs (D).

To realize the domain adaptation [8], we subtract the mean of the whole dataset from each embedding before the comparison. This also works even when the dataset that used to generate the mean is different from the target dataset.

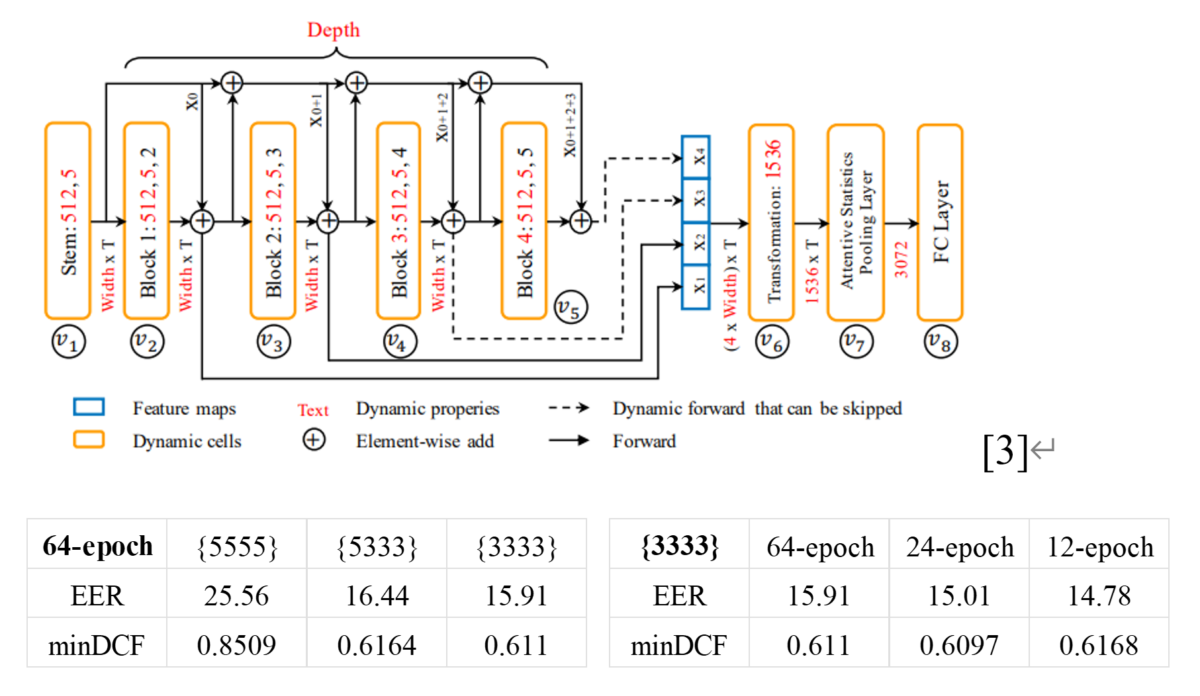
Also, since we are more interested in the performance on Chinese datasets, we train the Efficient-TDNN, which is three times smaller than the ECAPA-TDNN, with the cnceleb dataset. What’s more, we further train the Efficient-TDNN with both voxceleb and cnceleb datasets to see whether such model has the ability to handle both languages itself.
The table below shows the results on the cnceleb dataset by using the embeddings from the Efficient-TDNN trained with such dataset under dynamic architectures and different training epochs. We list the results of training the Efficient-TDNN model with both voxceleb and cnceleb datasets, too.

C. Speaker Retrieval
When it comes to details of the new-added quantization part, the overall loss function can be separated into two terms. The first term is the cross-entropy loss for the classification during training, and the second term is the L2 loss, which is added as a quantization loss. The target of the L2 loss is the integer 1 or -1, which forces the content of embeddings to be as close to 1 or -1 as they can, thus leads to a smaller influence while directly clamping them to 1 and -1. [9][10]
We use only the cnceleb dataset to fine-tune the Efficient-TDNN and starts from the checkpoint which has trained 64 epochs on the very model and dataset, but with the original loss function. First, we show the result on the speaker verification task.

For the speaker retrieval task, we utilize three different architectures to generate embeddings and inference on three datasets. The metric to evaluate the performance is mAP, which is defined as:
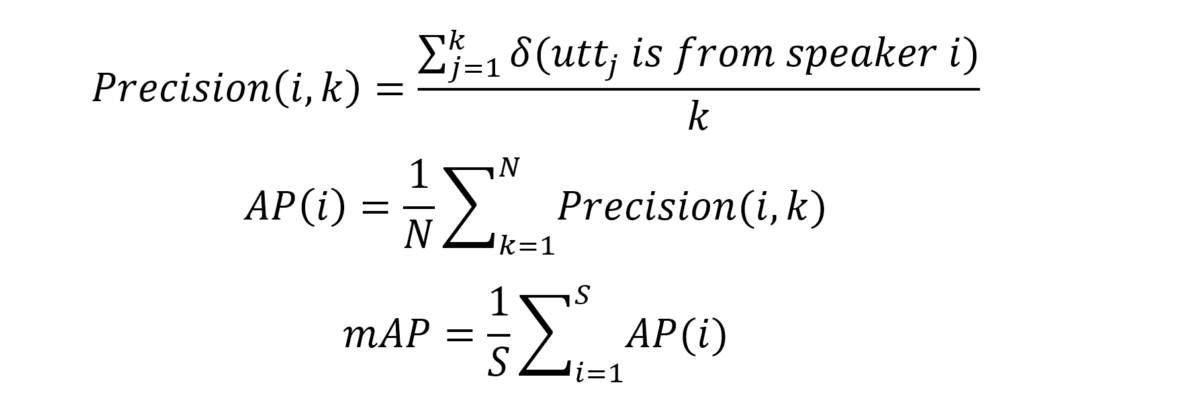
The detailed of three architectures are listed below. The first architecture is composed by HuBERT, an SSL model, followed with an additional linear layer, and a hyperbolic tangent layer. [11] The output of the hyperbolic tangent layer then uses to calculate the L2 quantization loss and used to calculate the cross-entropy loss after passing another linear layer. The second architecture uses the fine-tuned Efficient-TDNN mentioned above rather than the SSL model. Though the third architecture seems to be similar to the second one, it uses the 64-epoch pretrained model with the original loss function and thus generating floating number embeddings as a baseline for the quantization method. Note that the first architecture is trained on the voxceleb1 dataset while the other two are trained on the cnceleb dataset.
After the embeddings are generated, there are two ways for us to calculate distances between voice segments in the target set and those in the pool set, cosine distance for embeddings with floating numbers and hamming distance for those with quantized numbers. For the number of files in the pool set, we choose 10 files for each speaker in voxceleb2 and cnceleb datasets and choose all of the files in the voxceleb1 dataset. The experiment result is shown as below.
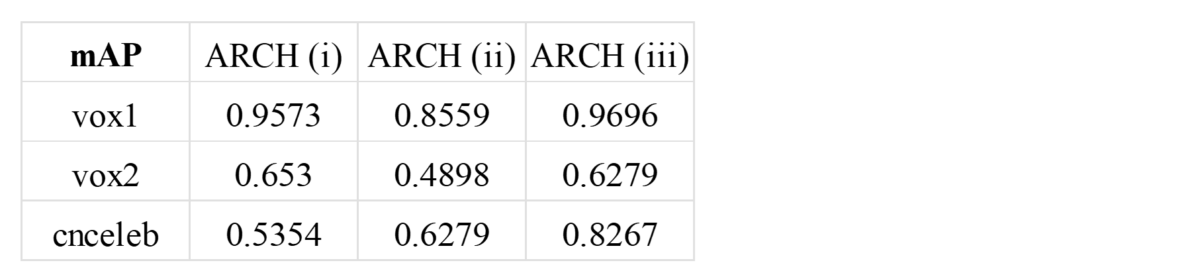
Despite that the performance of the quantization method has an approximately 11%~14% decrease compared to the baseline, the computation speed can gain a nearly 60% increase while calculating the distance and comparing through the pool set. What’s more, the memory usage can be significantly reduced, since a k-bit floating number requires k times of storage spaces than a boolean number.
D. Reference
[1] pyannote.audio: neural building blocks for speaker diarization
https://arxiv.org/abs/1911.01255
[2] A Comparison of Metric Learning Loss Functions for End-To-End Speaker Verification
https://arxiv.org/abs/2003.14021
[3] EfficientTDNN: Efficient Architecture Search for Speaker Recognition
https://arxiv.org/abs/2103.13581
[4] SpeechBrain: A General-Purpose Speech Toolkit
https://arxiv.org/abs/2106.04624
[5] VoxCeleb: a large-scale speaker identification dataset
https://arxiv.org/abs/1706.08612
[6] CN-CELEB: a challenging Chinese speaker recognition dataset
https://arxiv.org/abs/1911.01799
[7] FFSVC
[8] The SpeakIn System for Far-Field Speaker Verification Challenge 2022
speakin_22.pdf (ffsvc.github.io)
[9] Scalable Identity-Oriented Speech Retrieval
Scalable Identity-Oriented Speech Retrieval | IEEE Journals & Magazine | IEEE Xplore
[10] Deep Hashing for Speaker Identification and Retrieval
INTERSPEECH19_DAMH.pdf (jiangqy.github.io)
[11] Why does Self-Supervised Learning for Speech Recognition Benefit Speaker Recognition?