Lyrics-free Singing Voice Generation

The conventional approach to generate singing voices is through singing voice synthesis (SVS) techniques. A human user feeds lyrics and MIDI scores (a sequence of notes) to a well-trained SVS model, and the model generates audio recordings following the given lyrics and scores faithfully. The synthesis models have little freedom deciding what to “sing.”
In contrast to this conventional approach, we are interested in a singing voice generation model that does not take any lyrics and MIDI scores as input, but instead decides the phonemes and pitches underlying its singing pretty much on its own. We consider this setting as more interesting as it emphasizes the “creativity” of the model.
Accordingly, we chose to directly work on audio recordings without explicitly extracting pitches or lyrics from the singing audios. The first problem was how to gather enough singing voice audios in order to train neural network models. Luckily, we were experienced in music source separation and the music source separation can already separate the singing voices with reasonably good quality.
To allow the singing voice generation model to work together with our piano generation models (introduced here), we also want the model or a variant of it to sing according to a given piano track but not sing the exact notes of the piano track.
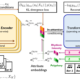
To model the singing voices, in the winter of 2019, we designed a GAN model that can generate singing voices freely as well as a variant of it that can sing along with a given accompaniment audio. Different from conventional GANs for image generation, the proposed model can generate audios with indefinite durations. This work was published in the International Conference on Computational Creativity (ICCC) 2020. This version of models will be referred to as the first generation.
The first generation of models produce very creepy singing voices that could make you have nightmares, so we developed the second generation of models. They were also GAN-based models, but the architecture and the vocoder were both improved. One particular extra mechanism is the cycle regularization, which largely improved the pronunciation and the intelligibility of phones. This work was published in INTERSPEECH 2020.
Although the sound quality was largely improved in the second generation, the generated singing voices did not sound good musically. Therefore, we started to build new models for better sequence modeling capability. Almost at the same time, OpenAI proposed JukeBox, a two-step method for music generation that directly worked on audios. In this two-step method, 1) an audio was converted into a sequence of discrete tokens with VQ-VAE, and 2) the tokens were modeled by a Transformer. In our third generation of models, we adopted this two-step method, while redesigning the architecture based on our goals.
One particular improvement was that the model can run in realtime. A variant of it could accompany the piano playing in realtime. The music team here at the Taiwan AI Labs has deployed it for realtime interaction in various exhibitions and art installations since the autumn of 2020.


We have been working on various improvements and variants of this model to have different usages for different applications. Our best model now can generate singing voices with quality much better than what described above. The new model is likely to make it debut soon. Stay tuned with us for more fun!
By: Jen-Yu Liu and Yi-Hsuan Yang (Yating Music Team, Taiwan AI Labs)