The Third-Party Federated Learning Model Interfacing
Ying-Chih Lin
Introduction
Federated learning(FL) is a deep learning approach that trains a model across multi-center without data circulation. Without the local training dataset exchangement in each center, the data can be well protected and more private. This technique enables one can train a robust model in the condition of data privacy, data security, and the right of data access which is suitable for the field of medical images. Medical images are the data collected from the screening records of patients from hospitals at all levels. As the images all come from patients, personal data protection is a serious issue while utilizing these data. FL is a state-of-art technique that can deal with these privacy problems by only sharing model parameters(including weights and biases of a model) between models that trained from each local server(edge). FL might stand an important role in the next generation of deep learning in medicine.
Model Introduction
The third-party model we brought from NYCU BSP/BML Lab led by professor Chen(陳永昇教授) is a binary classification model targeting 10 regions of the human brain. The Alberta stroke programme early CT score (ASPECTS) is a 10-point quantitative topographic CT scan score utilized in our model for evaluating the severity of ischemic stroke patients. By giving a noncontrast-enhanced CT(NCCT) image, the model can infer the severity of the patient.
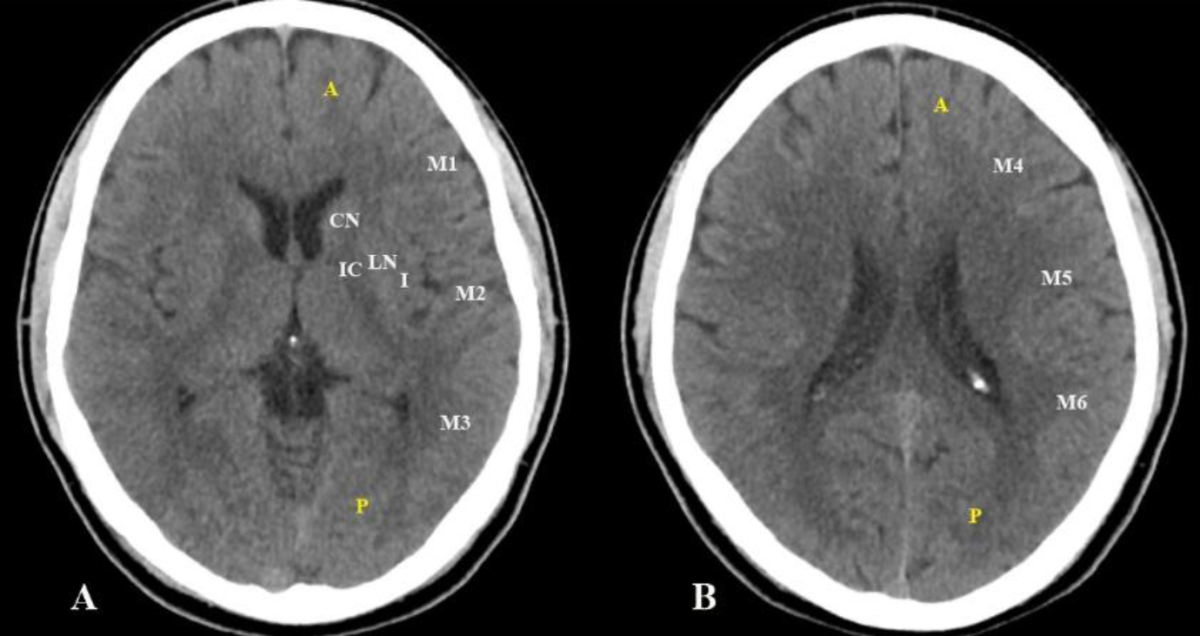
Figure of 10 regions of ASPECTS evaluation in the human brain
Source:https://radiopaedia.org/articles/alberta-stroke-programme-early-ct-score-aspects
Implementation
Our main task is to interface the third-party model into the FL system of AILabs. In stage one, we’ll need to be familiar with the Manual Harmonia(MH) system and the format of the model system needs while interfacing. Meanwhile, FL is a technique that requires communication between edges. In order to make sure every epoch of different edges is well trained before the next epoch of training starts, inserting multi-processing code in our original training code is necessary. After the first epoch is trained, models of all the edges need to load the model weights which merged by aggregator from all the last epoch models (ex: We get 2 edges in this task, both of the models in the 2 edges need to load the weights that merged from the 2 models of the first epoch by aggregator at the beginning of second epoch).
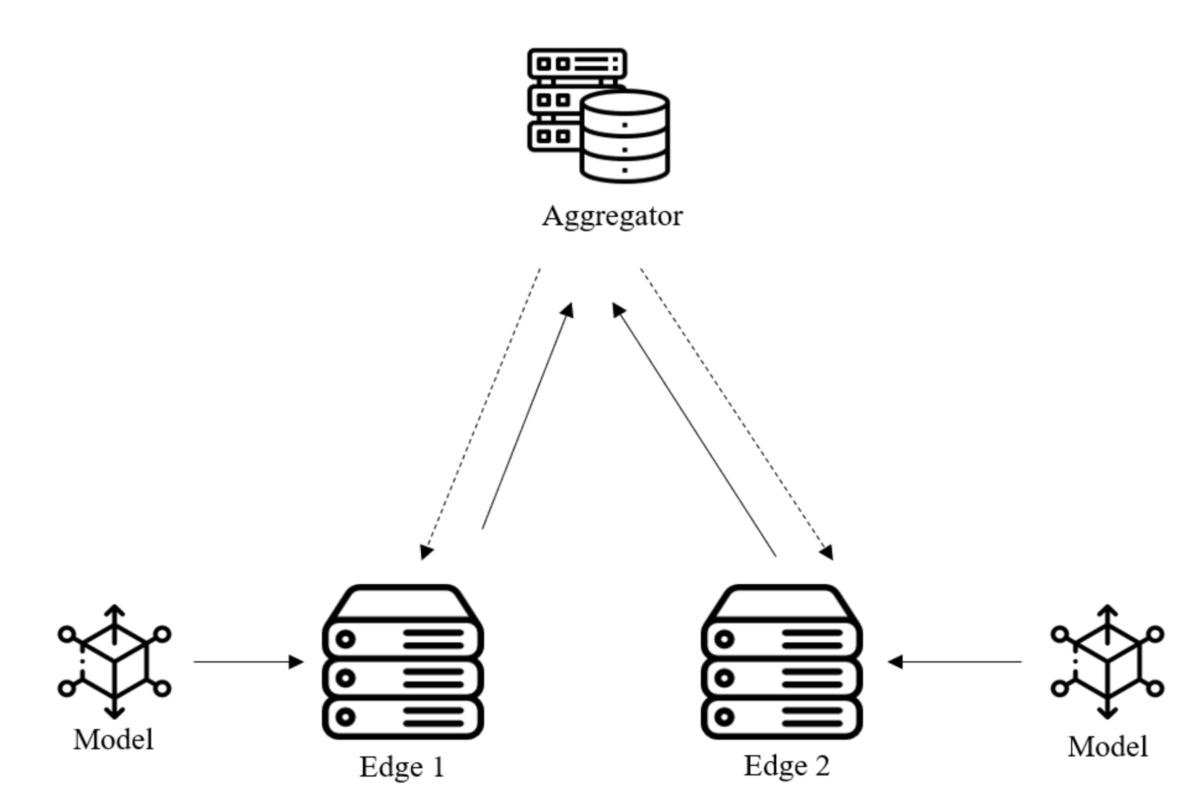
Figure of implementation in FL system
Finally, we got a file of model weights(merged.ckpt) at the end of the training. After evaluating the model performance, we put the whole training process actually in Physical which is stage two.
In this experiment, training dataset contained 170 3D NCCT images and 90 for testing. Half of the training data was divided into the 2 edges of FL(85/85). Final evaluation for the purpose of comparing the performance between NYCU local training and 2 edges of FL in AI Labs.
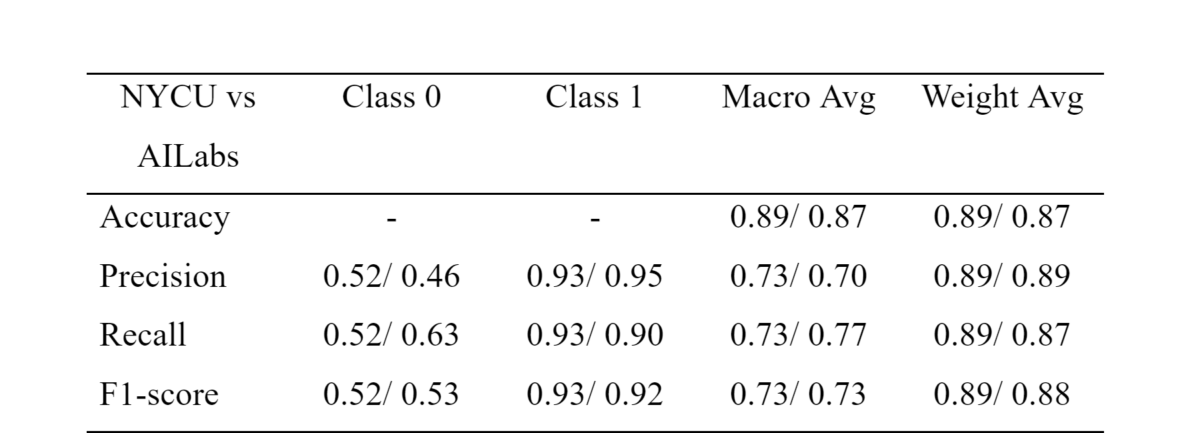
Table of performance comparison
Conclusion
We observed that the recall rate was a bit higher and the precision rate was a bit lower both in stage MH and stage Physical in Class 0. The final result of FL in AILabs showed the performance still maintained at the same level compared with local training in NYCU, which meant the task of interfacing is successful.

